 Forensic Authorship Attribution Pipeline
Forensic Authorship Attribution Pipeline
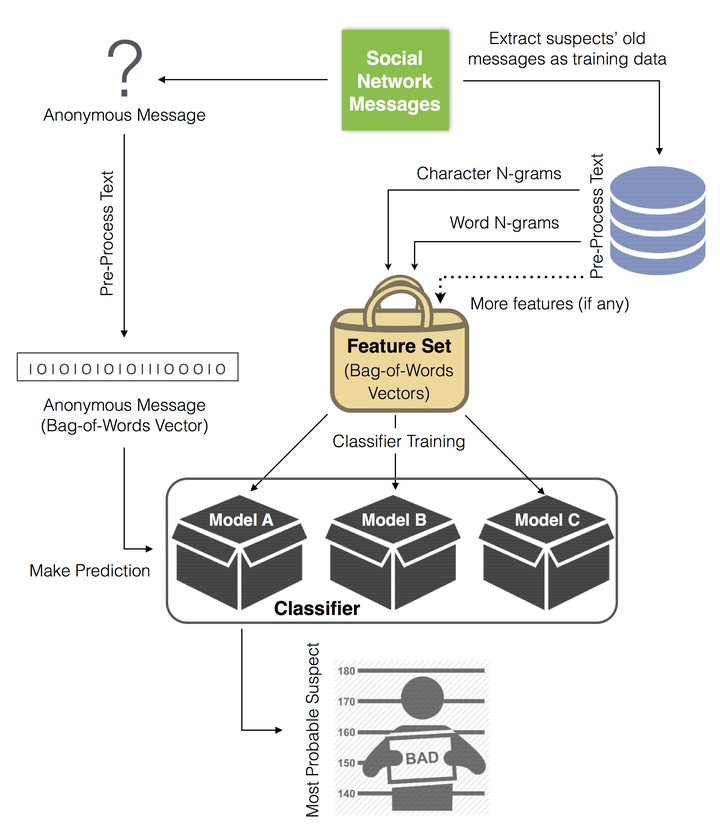
Abstract
The veil of anonymity provided by smartphones with pre-paid SIM cards, public Wi-Fi hotspots, and distributed networks like Tor has drastically complicated the task of identifying users of social media during forensic investigations. In some cases, the text of a single posted message will be the only clue to an author’s identity. How can we accurately predict who that author might be when the message may never exceed 140 characters on a service like Twitter? For the past 50 years, linguists, computer scientists, and scholars of the humanities have been jointly developing automated methods to identify authors based on the style of their writing. All authors possess peculiarities of habit that influence the form and content of their written works. These characteristics can often be quantified and measured using machine learning algorithms. In this paper, we provide a comprehensive review of the methods of authorship attribution that can be applied to the problem of social media forensics. Furthermore, we examine emerging supervised learning-based methods that are effective for small sample sizes, and provide step-by-step explanations for several scalable approaches as instructional case studies for newcomers to the field. We argue that there is a significant need in forensics for new authorship attribution algorithms that can exploit context, can process multi-modal data, and are tolerant to incomplete knowledge of the space of all possible authors at training time.
Antônio Theóphilo
Ph.D. Student
I am a Ph.D. student at the Institute of Computing/University of Campinas (UNICAMP) in the fields of Artificial Intelligence and Natural Language Processing. My research interests include Artificial Intelligence, Natural Language Processing, and Information Security.